
Por: Prashant Sharma e Richard Hagarty.
Atualizado em: 28 de março de 2019. | Publicado em: 27 de fevereiro de 2018.
Resumo
A análise de fluxo de cliques é o processo de coletar, analisar e gerar relatórios a respeito de quais páginas um usuário visita, o que pode oferecer informações úteis sobre características de uso de um site. Neste padrão de codificação, utilizaremos a análise de fluxo de cliques para demonstrar como detectar tópicos em tendência em tempo real no Wikipédia.
Descrição
A análise de fluxo de cliques é o processo de coletar, analisar e gerar relatórios a respeito de quais páginas um usuário visita, o que pode oferecer informações úteis sobre características de uso de um site.
Alguns usos populares desse tipo de abordagem incluem:
Testes A/B: estudo estatístico de como usuários de um site são afetados por mudanças de uma versão A para uma versão B;
Geração de recomendações em sites de venda: padrões de cliques de consumidores em um portal indicam como um usuário foi influenciado a comprar algo. Essa informação pode ser utilizada como geradora de recomendações para futuros padrões de cliques;
Publicidade direcionada: similar à geração de recomendações, é possível rastrear cliques do usuário em sites e utilizar essa informação para direcionar publicidade em tempo real e com mais eficiência;
Tópicos em tendência: a análise do fluxo de cliques pode ser utilizada para estudos ou geração de tópicos em tendência em tempo real. Considerando-se um intervalo de tempo em particular, é possível exibir os itens mais acessados para otimizar o número de cliques.
No padrão de codificação a seguir, demonstraremos como detectar tópicos em tendência em tempo real no Wikipédia. Para executar essa tarefa, utilizaremos o Apache Kafka como fila de mensagens, assim como o mecanismo de streaming estruturado Apache Spark para realizar a análise. Essa combinação é bem conhecida por características como usabilidade, alto rendimento e baixa latência.
Ao completar esse padrão, você vai entender como:
Utilizar o Jupyter Notebooks para carregar, visualizar e analisar dados;
Executar o Jupyter Notebooks no IBM Watson Studio;
Realizar uma análise de fluxo de cliques utilizando o mecanismo de streaming estruturado Apache Spark;
Construir um fluxo de processamento de baixa latência utilizando o Apache Kafka.
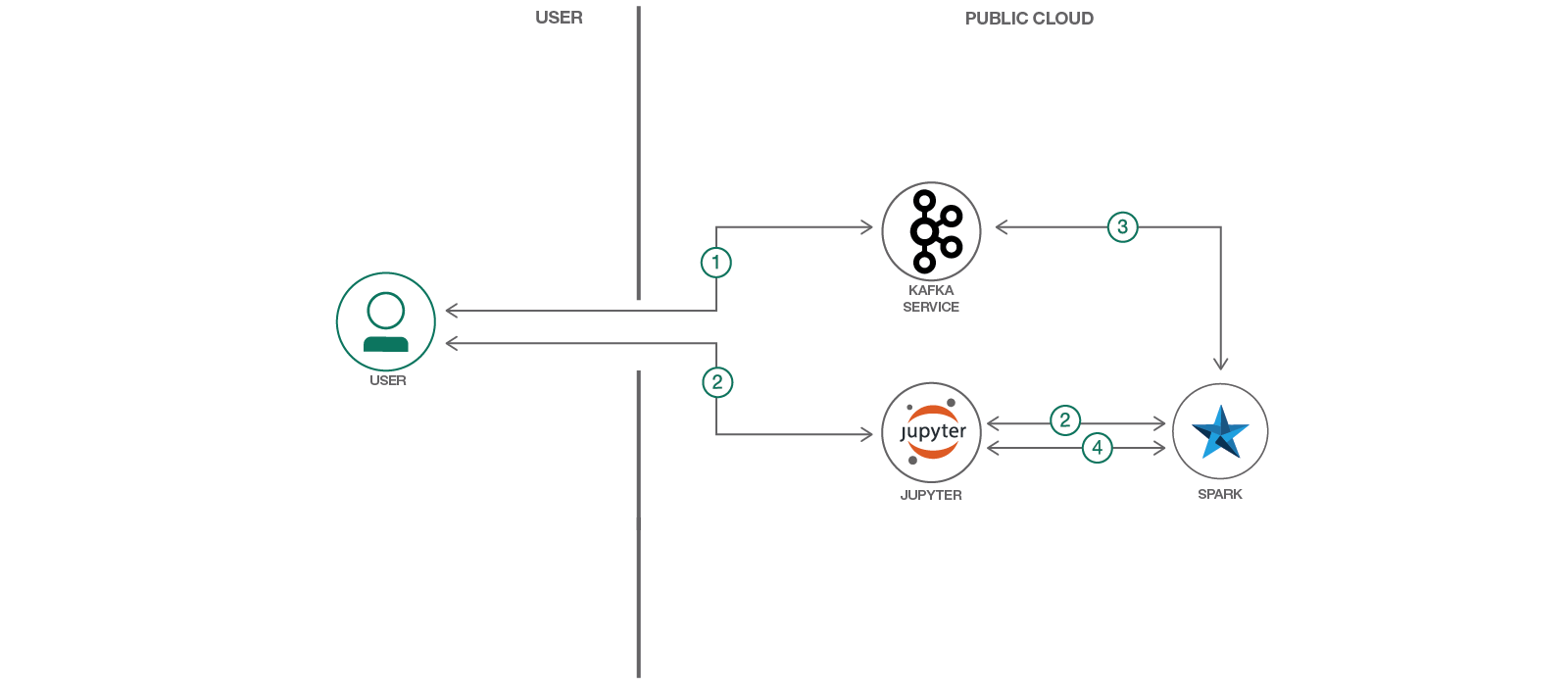 Usuário / Nuvem pública
Usuário / Nuvem pública
- 1. Conecte-se com o Apache Kafka e configure uma instância em execução de um fluxo de cliques;
- 2. Execute um Jupyter Notebook no Watson Studio que interaja com o serviço Apache Spark subjacente. Isso também pode ser feito localmente com o Spark Shell;
- 3. O Apache Spark carrega e processa os dados vindos do Apache Kafka;
- 4. Os dados processados são transmitidos novamente a você por meio do Jupyter Notebook (ou repositório de sink, no caso de execução local).
Instruções
Encontre o passo a passo detalhado deste padrão em README. Existem duas maneiras de exercitar essa habilidade:
Executando tudo localmente utilizando Spark Shell;
Utilizando o Jupyter Notebooks no IBM Watson Studio. Nota: para realizar esse tipo de abordagem, você precisará de um serviço Event Streams, que cobra taxas nominais.
...
Quer ler mais conteúdo especializado de programação? Conheça a IBM Blue Profile e tenha acesso a matérias exclusivas, novas jornadas de conhecimento e testes personalizados. Confira agora mesmo, consiga as badges e dê um upgrade na sua carreira!
Categorias






